Introduction
This is a challenge found on Kaggle.
We are given pictures of different types of cars (1918px x 1280px) and we would like to build a model to determine which pixels belong to the car and which do not. It is like finding the boundary of the car.
Using basic image techniques, auto-editing will do a pretty good job in finding where the boundary of the car is. But most of the time they could also capture the shadow of something in the background that is of very similar colour as the part of the car. Thus the company (Carvana) posed a challenge on Kaggle to build a model that correctly outline the boundary of the car.
The data given is a supervised machine learning task - they gave you the training data (the pictures of the car in a studio background) and the target mask (A mask that was drawn to outline the car in the pictures.)
The evalution metric is the dice coefficient, i.e. \(\frac{2|X\cap Y|}{|X|+|Y|}\), where \(X\) denotes the prediction pixels and \(Y\) denotes the target mask. \(|X\cap Y|\) means the number of correct prediction of where the mask is (we are not counting the correct prediction of where the mask should not be). It is similar to the F1 Score.
As I am seeking experience in coding machine learning tasks, this was a good practice for me to figure out what difficulties I would encounter when dealing with images and convolutional neural networks (CNNs).
Base Model
Our base model is to use ENet proposed by Adam Paszke, Abhishek Chaurasia, Sangpil Kim and Eugenio Culurciello in 2016. It is a model used for complicated semantic segmentation. To us, it was mostly an overshoot - but it is also a good way to try coding the model. We were looking at some sample code to further understand what the details of the model is. The model can be loosely described as below.
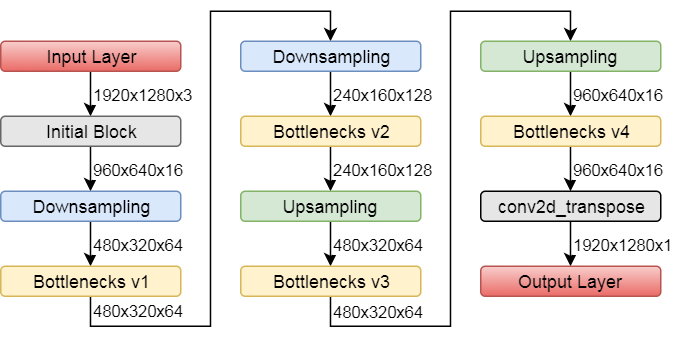
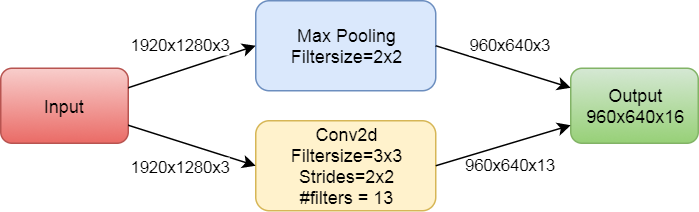
The initial block is as follows.
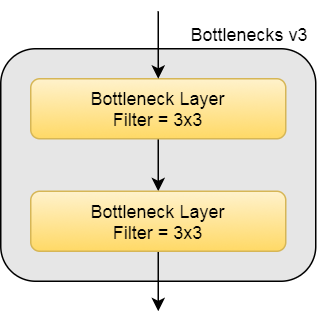
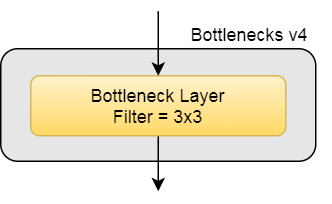
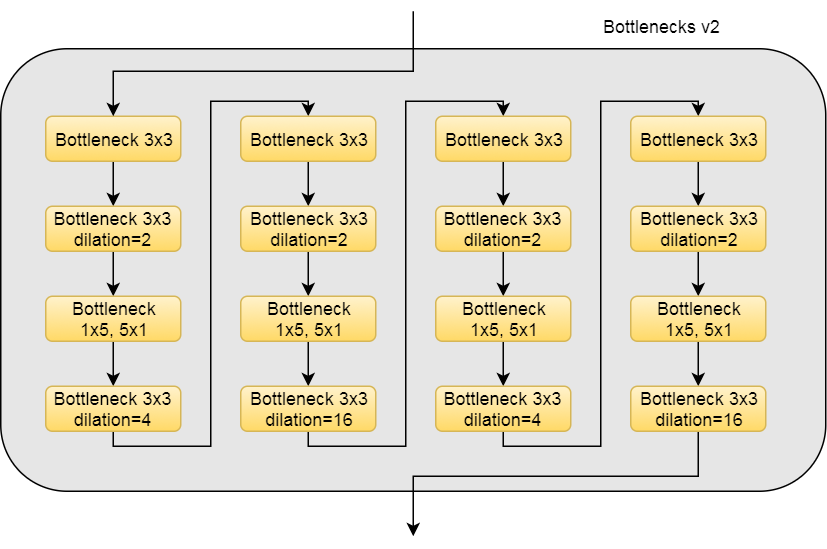
The general Bottleneck block is as follows.
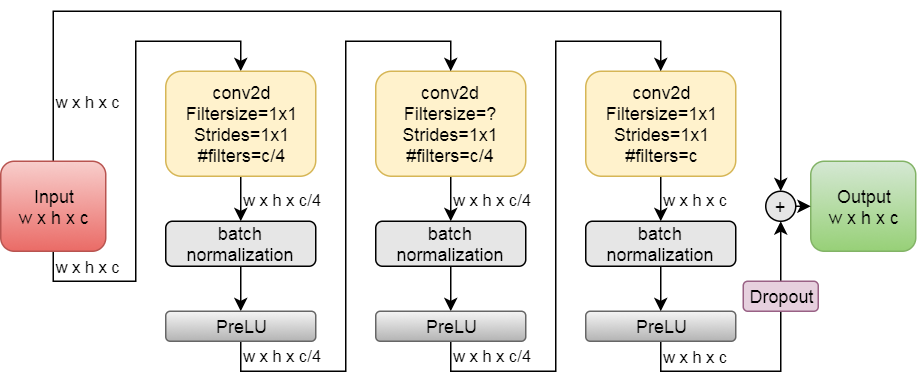
The bottleneck layer can be with various filters. Some of the bottleneck layers consist of dilated convolution, while some replace the middle conv2d layer with 2 conv2d layers with 1x5 followed by 5x1 filters
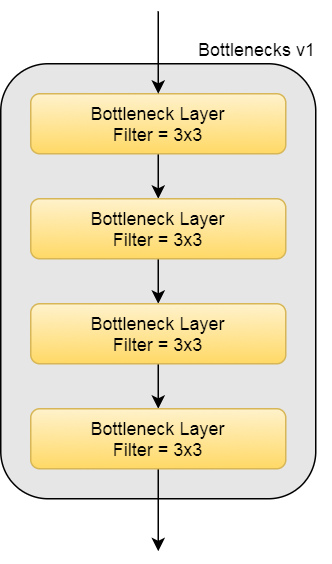
Here are the description of bottlenecks v1, v2, v3 and v4.
Difficulties
We tried to code this architecture, but we encountered a lot of difficulties.
Machine Requirements
The main difficulties we encountered is the machine requirements. First, in the downsampling bottleneck unit, what they did was not just to perform a maxpooling on the layer. They wanted to record where the max was in the pooling. The function tf.nn.max_pool_with_argmax just works for GPUs. As I do not have a GPU (my 2 graphic cards were Intel and AMD, sadly), I could not proceed with this function.
My machines are not very good as I just got 6 or 8 Gb of RAM. As a picture is 1920x1280 (We padded) with 3 channels (RGB), the size of 1 input picture will be in the order of millions of bytes. As I am building a neural network with about 40 layers, although the number of weights are not a lot because of the weight-sharing properties of CNNs, the forward propagation will take some time to compute, as well as the backward propagation. It also needs memory to store the states of the hidden units, which are huge in numbers. This causes very long training time. There were about 4500 training images. As we were using a minibatch size of 1 using the Adam Optimizer, on average, it took about 2 hours to finish 1 epoch of training. This is a very long time if I would like to learn how CNNs work. (Maybe it is not a very long time in advanced machine learning)
Logit Scales
Another problem we have encountered is that the scale of the logits increased by a factor of about 10 everytime when I added a bottleneck layer. In the beginning I tried to implement the initial layer and 1 or 2 bottleneck layers without downsampling and upsampling. It worked alright in terms of the running time, and the losses. However, when I tried to add 1 or 2 more bottleneck layers, the running time increases (of course) but the losses also increased by a factor of about 10. After I tried to implement 10 layers, the losses are in the order of magnitude of \(10^{10}\), and after some training steps, it exploded to NaN. I tried to adjust the learning rate and it does not help a lot.
Training Failed
My friend Geoffrey Scott first tried the ENet approach and it did not work for him. He said the training error does not seem to go down.
While he tried this project a few days ahead of myself, when I tried it, I kind of understood what happened. For me, the error was stuck in a region of 0.4 to 0.5 (after trying to fix all the above problems). As the minibatch size is 1, one cannot easily see the trend just by looking at the numbers. Also the training time is huge, we cannot see it at a certain time.
After a long wait and trying for different learning rate, we were happy that the error was going down very slowly from the 0.4 range to the 0.3 range - then 0.2 range - then 0.1 range - then smaller...but suddenly, possibly hit an exploding gradient, the error was in the 10 range. It goes down again to 0.4 to 0.5 range but after training for a very long time. It was stuck in the 0.4 to 0.5 and never went down again. This phenomenon is very weird. The only explanation we could think of is that even though the 0.4 to 0.5 range is the usual range, there are just a few of region in the weight space such that the training error will dscrease after some training steps. Thus we would have to run the model different times with different initializations.
Possible Fixes
We tried to "fix" the above problems - or rather, go around the problems.
Machine Requirements
The machine requirement problem is the hardest to fix - as we could not afford to buy a new very good machine just for this project. As I didn't have a GPU, we did not use the tf.nn.max_pool_with_argmax function. Instead we did not record the position of the argmax when we were downsampling using maxpool. During the upsampling phase, or the unpooling phrase, we just unpool it without the argmax by expanding the pixel into 2x2 pixel of the same values. This is different from the original ENet, but I was to try if this method works, at least to an extent, almost well.
For the memory requirements, what we did was to explore different options.
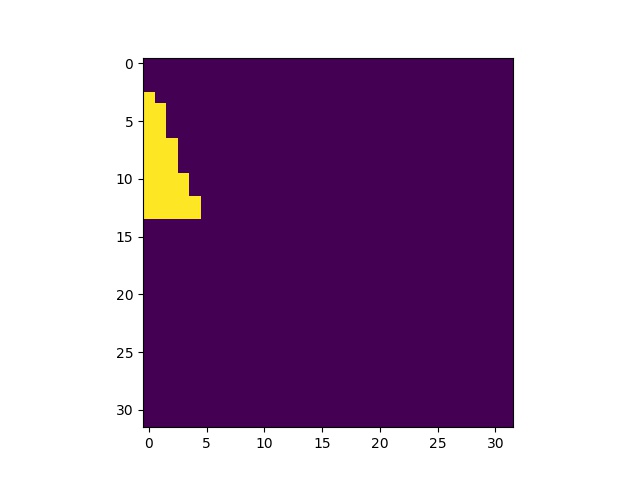
- My first method was to decrease the resolution of the image - to resize it to 480x320. The size was supposed to be one-sixteenth of the original picture size and it could fit my memory during training using a minibatch of 1. (Previously my computer crashed) I did not plan on what I should do after I found a mask that is 480x320. I was thinking of just unpooling each pixel to a 4x4 uniform square.

Before Unpool (24x16) 
After Unpool (1920x1280)
Note that the pictures above was to unpool each pixel to a 80x80 square instead of a 4x4 square for demo purpose.
def unpoolarray(inputs,m): inputs = np.array(inputs) return inputs.repeat(m,0).repeat(m,1) - We were also thinking of doing a smoothing operator on the unpooled 1920x1280 mask - by applying a average filter of size (3x3 or 2x2) to smoothen the image. It increased the average dice score by a very very very small amount though.

Original (Predicted) Mask 
Smoothed with mask size 5x5 
Smoothed with mask size 10x10 
Smoothed with mask size 20x20
We can see that the smoothed image looks much better than the original mask (not the given ones). A disadvantage for this smoothing operator is that it will erase any delicate part of the car, like antennae.
def smooth(pic, size): from scipy import signal pic=pic.astype('float') w = np.ones((size,size), dtype ='float') a=signal.convolve2d(pic,w,'same') b=signal.convolve2d(1-pic, w,'same') return a-b>0 Instead of unpooling to a 4x4 uniform square, one can see if we can use the "blurred" mask, or smaller mask of 480x320, to guess the approximate boundary of the car. Then for each boundary points, one pass through a nearby square to a new neural network to train with more precision. This is supervised learning because we have the target mask.
The size of the square can be determined. The followings list some of the "boundary squares"
Let's isolate one square.
Smallest boundary squares. A lot of squares! 
Mid-sized boundary squares 
Big boundary squares 
Small square of Predicted Mask We would like to make the square of the original image an input and pass it in a neural network. This means the following will be the input of a separate network.
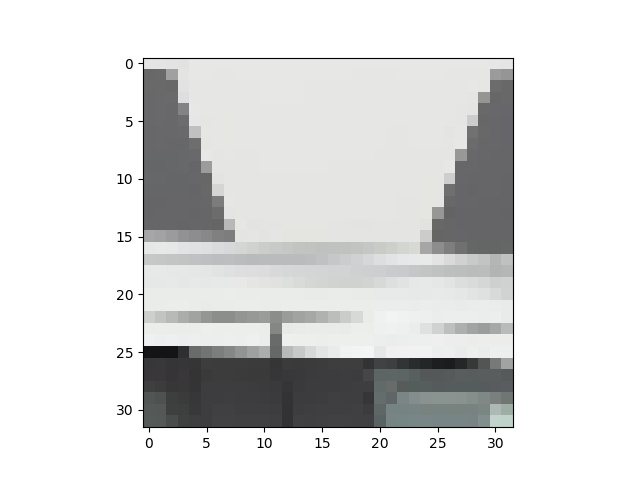
As we can see that this method may not work very nicely as if you give me a small "nearby square", we may not be able to tell which part belongs to the car and which part does not belong to the car. If you just look at the above image, there is no way you can tell that which parts belong to the car and whch do not. There are two possible fixes to this problem.
- We could use a bigger nearby square. Maybe 32x32 or even 64x64; or
- We could use a the predicted mask in the boundary of the square and tried to give information about what part of the colour patch belongs to the car, even looking at a very small square. We include the predicted mask of the boundary as inputs. (Basically this method is similar to a bigger nearby square)

Bigger boundary square 
Neighbour pixels considered Sadly, none of these methods worked very well. The loss of the second neural network did not decrease after training and it worked badly.
-
Geoff used a different method. He resized the image to 160x80 as the inputs, and used a fully connected neural network, with some hidden layers, to the output of the same size. He discovered that his computer could handle that. After that he selected the boundary pixels in the mask (more accurately, he selected the pixels based on the probability of the pixel of being the car - if the probability is greater than 0.05 and less than 0.95, then we can say the machine is not very confident in determining if the pixel belonged to the car.), and passed it through a second neural network. The input of the neural network was the 16x16 square (in the original image) corresponding to the pixel in the 160x80 mask, plus 8 adjacent 16x16 square corresponding to the nearby pixel, but with a smaller resolution (thus the 16x16 is actually a 8x8 after resizing), and the 16 2-tier adjacent \(d_\infty = 2\) tiles with even smaller resolutions (4x4), etc.
Fix a boundary square 
Geoff's method We can see that he used full resolution on the middle square, then half resolution on the yellow squares, then one-fourth of the resolution on the red squares, and so on.
He was able to achieve a 0.985 dice score on his test set.
Perhaps the best way to "fix" the machine requirements problem is to use some cloud platforms. We used the Google Cloud Platform as we got a US$300 credit for new users. They even had GPU in the virtual machine (on selected zones). The downside is that we were completely new to the cloud platform and the virtual machines (with linux) - thus we spent a fair amount of time figuring how to run my code on the virtual machine - and how to set up the GPU. It turned out that this was not a downside but an upside for me - because we are now now familiar with the linux environment, command lines, and GCP of course. On the machine, we were able to run our ENet with tf.nn.max_pool_with_argmax using the original image size. Although we were able to run, the runtime is the same when we ran the 480x320 size. It is possible, but it was not ideal. Instead we used the smaller size image with a GPU to decrease the training time and that was the final model we used, with tf.nn.max_pool_with_argmax though.
Logit Scales
To fix the logit scales issue, we divide the output of each bottleneck by 10, and some other units by 100. The final logits were in a comfortable range and it finally did not blow up, and started training. Because of this phenomenon, we did a more in-depth survey on this matter, here.
It is also advised to check your code for bugs if the logit scales up enormously. In our case, we discovered a bug that would alter every bottleneck units.
Training Failed
Another huge problem is the failure of training. The go-to method I used was to tune down the learning rate from 0.01 to 0.001. The training error started to decrease from 0.5 to 0.1 and stayed there, without encountering an exploding gradient. That time, we tune down the learning rate, manually, to 0.0003, 0.0001 or even \(3\times 10^{-5}\) or \(1\times 10^{-5}\). The final training error was about 0.02. Since each epoch took about 2 hours at the start and about 20 minutes when we used Google Cloud Platform, we have to tune it down manually because sometimes we were still experimenting about the learning rate.
The frustrating thing came when we discovered we could use the full resolution using the Google Cloud Platform. It took 2 hours per epoch, but no matter how many different learning rates I tried, the training error was stuck on the 0.4 to 0.5 range. The predicted mask was completely random, even we tried different initializations and learning rate. After a while we gave up and used the 480x320 model.
Another reason for the training to fail is the problem with the model. It would be good to design a model that fit with the current task. As ENet was widely used for semantic segmentation, the model should be fine. Then to fix the training problem, one should look carefully at the code to see if there was any mistake in it. In our case, we fixed a simple bug that altered every bottleneck unit.
Additional Methods
These methods are not machine learning methods, but only image processing methods. They were all used for postprocessing the predicted mask.
Our model did not give the best mask. Instead there were a lot of places which the model gave masks for some random pixels in the background, and not giving masks for some random pixels on the car (mainly at the windows). Luckily these pixels are very small patches and we had a fix on this. The method was to select the biggest connected component of the "mask" part to label those as being a part of the mask, with all the other smaller connected components of the "mask" being labelled as being not a part of the mask. Then we did the reverse - looking at the connected components of the "nonmask" part. This significantly increased the dice score on our test sets.

Before. Dice score: 0.97788544 
After. Dice score: 0.98545455 We can see that in the image on the left, we predicted some pixels in the middle of the car to be nonmask (not a car). We also predicted that some pixels on the floor belong to the car. We can see the the above "clearing minor connected component" method will clean this up.
Sometimes, a whole window part of the car was incorrectly being labelled as "non-mask". Although this could be fixed use the above "connected component" method, sometimes the window is connected to the outside background through a very small gap and thus the above method would not work. Instead, before we did the above "connected component" method, we did the following.
- Apply a max filter of a fix size to the mask. This "thickens" the mask.
- Apply a min filter of the same size to the thickened mask. This "shrinks" the mask.
- Apply a min filter of the same size again, then apply the max filter again.
We can see some sample results below. It also cleared up some "holes". This also increased the dice score on our test sets.
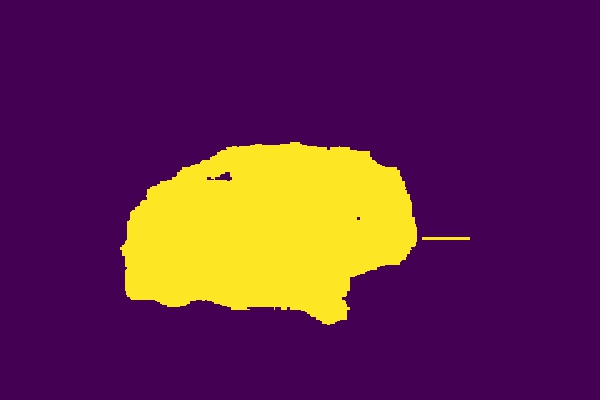
Before. Dice score: 0.97625215 
After first thickening. Dice score: 0.95857402 
After first shrinking. Dice score: 0.97719329 
After second shrinking. Dice score: 0.96521846 
After final thickening. Dice score: 0.97894987 
Comparison to "before" (New only:red, Old only:blue) - There was a very complicated refinement operation that would also increased the dice score of the test set. The steps are the followings.
- First we did the postprocessing steps described above.
- We unpooled the 480x320 mask to 1920x1280 mask.
- We used the
skimage.filters.sobelpackage to find the boundary, then did a maxpooling with fixed filter size (16x16 or 8x8 or 32x32). Thus each pixel with boundary "on" (we had a threshold), it corresponds to a square of the filter size within the image and the mask. -
We looked at each square of the image and used
skimage.filters.sobelagain to find the boundary. We found the connected components of the pixels that was NOT labelled as the boundary.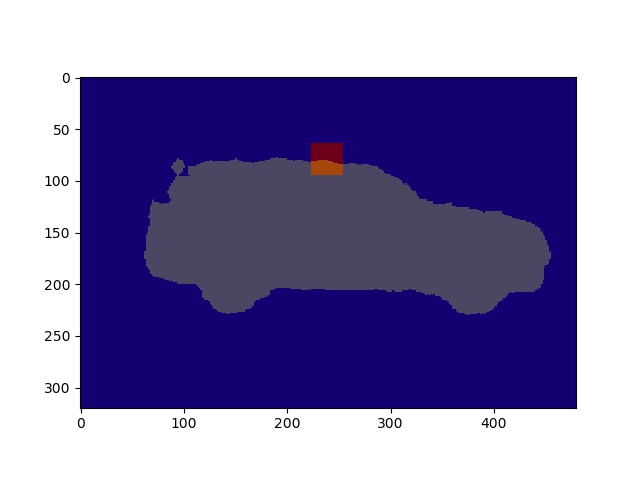
A square corresponding to a boundary point
Single the square out 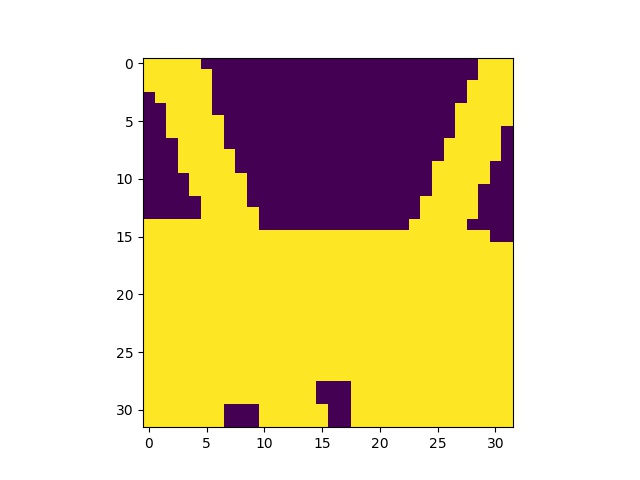
Yellow denotes a "boundary point" 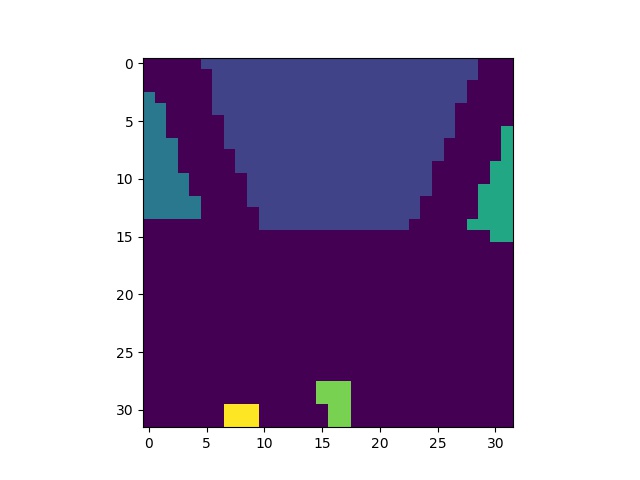
Connected components of "non-boundary" - For each connected components, we say that they either all belong to the car, or they all do not belong to the car
- To determine which one, we looked at our predicted mask. We made a decision of that connected component based on two criteria.
- The number of "mask" pixels vs the number of "nonmask" pixels in the predicted mask within the connected component.
If ther connected component included the boundary of the square, we looked at the number of "mask" pixels and "nonmask" pixels in the predicted mask just outside boundary of the square. If it does not include the boundary of the square, we ignore this criteria.
Single a connected component of "non-boundary" 
compare the yellow pixels and their neighbour pixels out of the square
- We determine if the connected component is "mask" or "nonmask" based on a weighted score of the above two criteria.
Results and Conclusion
Our result was a huge csv file of size about 1Gb, which was the norm. The average dice score of our model was about 0.96 to 0.97, which was not nearly as good as the top models.
We would like to try more using a better computer and GPU to the original size and see if it started to train.
We included some of our results below.






Unfortunately, we discovered a bug in the code while cleaning up the code - after the competition deadline. We re-ran the code on a GPU and it only took 1 day to reduce the training error to a very nice range (about 0.005). The logits did not blow up and we don't have to do a lot of postprocessing. The only postprocessing was to unpool the 480x320 masks into 1920x1280 masks, then apply a smoothing operator of size 3 as described above. The final average dice score of our set is 0.992. Here are some of the examples shown.

More demo on the demo page.
Code
import numpy as np
import pandas as pd
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import time
import sys
import tensorflow as tf
from skimage.measure import label
from skimage.transform import resize
from skimage.filters import sobel
from tensorflow.contrib.layers import xavier_initializer
global path
import scipy
path = '/home/'
def prelu(x, decoder=False):
if decoder:
return tf.nn.relu(x)
alpha = tf.Variable(0.0, x.get_shape()[-1])
pos = tf.nn.relu(x)
neg = alpha * (x - abs(x)) * 0.5
return pos + neg
def initial(inputs):
net_add = tf.layers.max_pooling2d(inputs=inputs,pool_size=[2, 2],strides=2)
net_conv = tf.layers.conv2d(inputs=inputs,
filters=13,
kernel_size=[3, 3],
strides=(2,2),
padding="same",
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
return tf.concat([net_conv, net_add], axis=3)
def bottleneck(inputs, filtersize, keepprob, dilation=1, istraining=True):
shape = inputs.get_shape().as_list()
net_add = inputs
net = tf.layers.conv2d(inputs=inputs,
filters=shape[-1]//4,
kernel_size=[1,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
dilation_rate=(dilation, dilation),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=shape[-1]//4,
kernel_size=[filtersize, filtersize],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
dilation_rate=(dilation, dilation),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=shape[-1],
kernel_size=[1,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
dilation_rate=(dilation, dilation),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
if istraining:
net = tf.nn.dropout(net, keepprob)
return tf.add(net, net_add)
def asymmetric(inputs, filtersize, keepprob,istraining=True):
shape = inputs.get_shape().as_list()
net_add = inputs
net = tf.layers.conv2d(inputs=inputs,
filters=shape[-1]//4,
kernel_size=[1,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=shape[-1]//4,
kernel_size=[1, filtersize],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.conv2d(inputs=net,
filters=shape[-1]//4,
kernel_size=[filtersize,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=shape[-1],
kernel_size=[1,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
if istraining:
net = tf.nn.dropout(net, keepprob)
return tf.add(net, net_add)
def downsample(inputs, outdepth, keepprob,istraining=True):
shape = inputs.get_shape().as_list()
net_add, pooling_indices = tf.nn.max_pool_with_argmax(inputs,
ksize=[1,2,2,1],
strides=[1,2,2,1],
padding='SAME')
paddings = tf.convert_to_tensor([[0,0], [0,0], [0,0], [0, outdepth - shape[-1]]])
net_add = tf.pad(net_add, paddings=paddings)
net = tf.layers.conv2d(inputs=inputs,
filters=shape[-1]//4,
kernel_size=[2,2],
strides=(2,2),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=shape[-1]//4,
kernel_size=[3,3],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=outdepth,
kernel_size=[1,1],
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
if istraining:
net = tf.nn.dropout(net, keepprob)
return tf.add(net, net_add), pooling_indices
def unpool(updates, mask, ksize=[1, 2, 2, 1]):
'''
Unpooling function based on the implementation by Panaetius at
https://github.com/tensorflow/tensorflow/issues/2169
'''
mask = tf.cast(mask, tf.int32)
input_shape = tf.shape(updates, out_type=tf.int32)
# calculation new shape
output_shape = (input_shape[0], input_shape[1] * ksize[1], input_shape[2] * ksize[2], input_shape[3])
# calculation indices for batch, height, width and feature maps
one_like_mask = tf.ones_like(mask, dtype=tf.int32)
batch_shape = tf.concat([[input_shape[0]], [1], [1], [1]], 0)
batch_range = tf.reshape(tf.range(output_shape[0], dtype=tf.int32), shape=batch_shape)
b = one_like_mask * batch_range
y = mask // (output_shape[2] * output_shape[3])
x = (mask // output_shape[3]) % output_shape[2]
feature_range = tf.range(output_shape[3], dtype=tf.int32)
f = one_like_mask * feature_range
# transpose indices & reshape update values to one dimension
updates_size = tf.size(updates)
indices = tf.transpose(tf.reshape(tf.stack([b, y, x, f]), [4, updates_size]))
values = tf.reshape(updates, [updates_size])
ret = tf.scatter_nd(indices, values, output_shape)
return ret
def upsample(inputs, outdepth, filtersize,pooling_indices, keepprob,istraining=True):
#from tensorflow.contrib.layers.python.layers import initializers
shape = inputs.get_shape().as_list()
net_add = tf.layers.conv2d(inputs=inputs,
filters=outdepth,
kernel_size=[1,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net_add = tf.layers.batch_normalization(net_add)
net_add = unpool(net_add, pooling_indices)
net = tf.layers.conv2d(inputs=inputs,
filters=shape[-1]//4,
kernel_size=[1,1],
strides=(1,1),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net_unpool_shape = net_add.get_shape().as_list()
net = tf.layers.conv2d_transpose(inputs=net,
filters=shape[-1]//4,
kernel_size=[filtersize,filtersize],
strides=(2,2),
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
net = tf.layers.conv2d(inputs=net,
filters=outdepth,
kernel_size=[1,1],
padding='same',
activation=None,
kernel_initializer=xavier_initializer(),
use_bias=False)
net = tf.layers.batch_normalization(net)
net = prelu(net)
if istraining:
net = tf.nn.dropout(net, keepprob)
return tf.add(net, net_add)
def enet(X, training):
net = initial(X)
net, poolin1 = downsample(inputs=net,outdepth=64,keepprob=0.99,istraining=training)
for i in range(4):
net = bottleneck(inputs=net,filtersize=3,keepprob=0.99,istraining=training)
net, poolin2 = downsample(inputs=net,outdepth=128,keepprob=0.9,istraining=training)
for i in range(2):
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,dilation=2,istraining=training)
net = asymmetric(inputs=net,filtersize=5,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,dilation=4,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,dilation=8,istraining=training)
net = asymmetric(inputs=net,filtersize=5,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,dilation=16,istraining=training)
net = upsample(inputs=net,outdepth=64,filtersize=3,pooling_indices=poolin2,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,istraining=training)
net = upsample(inputs=net,outdepth=16,filtersize=3,pooling_indices=poolin1,keepprob=0.9,istraining=training)
net = bottleneck(inputs=net,filtersize=3,keepprob=0.9,istraining=training)
return tf.layers.conv2d_transpose(inputs=net,filters=1,kernel_size=[2,2],strides=(2,2))
def testsplitfiles(percent, random_seed=None):
'''percent: percentage of training data in all data.
get a list of all files in the directory and split them into train and validation.
Output a list of filenames for training data and validation data'''
import os
b=pd.Series(os.listdir(path+'train'))
b=b[:-1]
from sklearn.utils import shuffle
i=int(len(b)*percent)
b=shuffle(b, random_state=random_seed).reset_index().iloc[:,1]
return b[:i], b[i:]
def maxpool(inputs):
'''Perform 2x2 maxpooling for the inputs.'''
h,w = inputs.shape
return np.amax([inputs[(i>>1)&1::2,i&1::2] for i in range(4)],axis=0)
def resizecar(img,aspect):
'''Resize Car by a factor. For example if car is 1920x1280 resizecar(car, 4) will give 480x320'''
x=img.shape
if len(x)==2:
return resize(img, (x[0]//aspect, x[1]//aspect), mode = 'reflect')
if len(x)==3:
return np.array([resize(img[:,:,0], (x[0]//aspect, x[1]//aspect), mode = 'reflect'),
resize(img[:,:,1], (x[0]//aspect, x[1]//aspect), mode = 'reflect'),
resize(img[:,:,2], (x[0]//aspect, x[1]//aspect), mode = 'reflect')]).transpose([1,2,0])
def readcar(filename, gray=False, aspect = 4, test=False):
'''gray: Grayscale or not,
aspect: How much shrinkage,
test: False for training data and validation data, True for test data
'''
if test:
file = path+'test/'+filename
else:
file=path+'train/'+filename
car=mpimg.imread(file)
if gray:
car = np.dot(car[:,:,:3], [0.299, 0.587, 0.114])
return resizecar(car,aspect)
def readcarmask(filename, aspect = 4):
file=path+'train_masks/'+filename[:-4]+'_mask.gif'
return resizecar(mpimg.imread(file)[:,:,0],aspect)
def readmaskfiles(filelist,index=0,small=True):
'''Read the file in the index of the filelist. Return an [1,320,480,1] image
If small=False, return an original carmask with padding
'''
if not small:
carmask = readcarmask(filelist.iloc[index], aspect=1)/255
carmask = np.pad(carmask, ((0,0), (0,2)), mode='reflect')
return carmask
carmask = readcarmask(filelist.iloc[index])
carmask = np.concatenate((carmask, carmask[:,-1:]),1)
carmask = carmask.reshape(1,1280//4,1920//4,1)
return carmask
def readmaskbatch(filelist, index, numfiles, small=True):
'''Return an [n,320,480,1] object with n masks.
n=numfiles or till the end of the filelist depending on the index'''
li=[]
if index+numfiles>len(filelist):
num= len(filelist) - index
else:
num = numfiles
for j in range(num):
li.append(readmaskfiles(filelist,index+j, small=small))
return np.array(li).reshape(num, 1280//4, 1920//4, 1)
def preprocesscar(img,small=True, gray = False):
'''Similar to readmaskfiles, but with car.'''
if not small:
car = np.pad(img, ((0,0), (0,2), (0,0)), mode='reflect')
return car
if len(img.shape)==2:
car = np.concatenate((img, img[:,-1:]),1)
car = car.reshape(1,1280//4, 1920//4,1)
elif len(img.shape)==3:
car = np.concatenate((img, img[:,-1:,:]),1)
car = car.reshape(1,1280//4, 1920//4,3)
return car
def readcarbatch(filelist,index,numfiles,small=True, gray=False):
'''Similar to readmaskbatch, but with cars'''
li=[]
if index+numfiles>len(filelist):
num = len(filelist) - index
else:
num = numfiles
for j in range(num):
li.append(preprocesscar(readcar(filelist.iloc[index+j], gray=gray, aspect=4)))
return np.array(li).reshape(num, 1280//4, 1920//4, 3)
def findsquare(img,inputs, aspect=0,sqsize=32):
'''Find the square in the original image corresponding to a pixel in a small image. For example,
if the inputs are [2,7] and the sqsize is 32, it will output [2*32:3*32, 7*32:8*32]
Aspect is the d_infty distance determining how many adjacent squares will that also be included. '''
xl,yl = (inputs[0])*sqsize, (inputs[1])*sqsize
xr, yr = (inputs[0]+aspect*2+1)*sqsize, (inputs[1]+aspect*2+1)*sqsize
if len(img.shape)==2:
imge = np.pad(img, ((aspect*sqsize, aspect*sqsize), (aspect*sqsize, aspect*sqsize)), mode='reflect')
return imge[xl:xr,yl:yr]
if len(img.shape)==3:
imge = np.pad(img, ((aspect*sqsize, aspect*sqsize), (aspect*sqsize, aspect*sqsize),(0,0)), mode='reflect')
return imge[xl:xr,yl:yr,:]
def getlist(mask,maxpoolnum=5):
'''Get a list of all boundary squares in a mask. The square size is 2^(maxpoolnum).'''
filt = (sobel(mask) > 0).astype(int)
for i in range(maxpoolnum):
filt = maxpool(filt)
li= pd.DataFrame(np.argwhere(filt==1))
li= li[li.iloc[:,0]>0]
li= li[li.iloc[:,1]>0]
li= li[li.iloc[:,0]<39]
li= li[li.iloc[:,1]<59]
return np.array(li)
def thicken_shrink(inputs,pixel):
out = scipy.ndimage.filters.maximum_filter(inputs,pixel)
return scipy.ndimage.filters.minimum_filter(out,pixel)
def findcc(mask):
#pick the largest connected component of mask
alllabel = label(mask, background=-1)
pixelmasklabel = pd.Series((alllabel * mask).reshape(-1))
mask = (alllabel==pixelmasklabel[pixelmasklabel>0].value_counts().index[0])
#pick the largest connected component of nonmask
alllabel = label(mask, background=-1)
pixelnonmasklabel = pd.Series((alllabel * (1-mask)).reshape(-1))
return 1 - (alllabel==pixelnonmasklabel[pixelnonmasklabel>0].value_counts().index[0])
def unpoolarray(inputs,m):
'''unpool with filtersize m x m'''
inputs = np.array(inputs)
return inputs.repeat(m,0).repeat(m,1)
def dice(im1, im2):
'''Compute the dice score'''
im1 = np.asarray(im1).astype(np.bool)
im2 = np.asarray(im2).astype(np.bool)
if im1.shape != im2.shape:
raise ValueError("Shape mismatch: im1 and im2 must have the same shape.")
intersection = np.logical_and(im1, im2)
return 2. * intersection.sum() / (im1.sum() + im2.sum())
def showmask(car, mask):
'''Show a picture of a car and a mask on top of it'''
plt.imshow(car)
plt.imshow(mask, 'jet', alpha=0.7)
plt.show()
return None
def refinemask(car, mask,threshold=0.01, split=0.9, dim = 32,param=2.5):
'''threshold: the threshold to be considered as a boundary
split: weights of edgescore and maskscore
params: decision threshold for totalscore of zero and totalscore of one'''
m = mask.copy()
coordlist=getlist(m, maxpoolnum=int(round(np.log(dim)/np.log(2))))
for coord in coordlist:
x,y = coord
#initialization
edges=np.zeros((dim+2,dim+2)).astype(bool)
#Find the portion of the car and mask that corresponds to the square, with border 1
carsmall=findsquare(car,coord,aspect=1,sqsize=dim)[dim-1:2*dim + 1,dim-1:2*dim+1,:]
masksmall=findsquare(m, coord, aspect=1,sqsize=dim)[dim-1:2*dim+1,dim-1:2*dim+1].astype(bool)
#find the "boundary points" of the small squares and thicken it
for i in range(3):
temp=sobel(carsmall[:,:,i])
temp=(temp>threshold)
edges = edges | temp
edges=scipy.ndimage.filters.maximum_filter(edges,2)[1:-1,1:-1].astype(int)
#label each connected component of the "non-boundary points"
lab, num=label(edges, background=1,return_num=True)
maskcopy=masksmall[1:-1,1:-1].copy()
for i in range(1,num+1):
#Compute the number of pixels that intersect the boundary of the square of each connected component
edgenum=((lab==i)[(0,-1),:]).sum() + ((lab==i)[:,(0,-1)]).sum()
if edgenum>0:
#compute edge score if there is an intersection
edgescore1=((lab==i)[(0,-1),:] & masksmall[(0,-1),1:-1]).sum() \
+ ((lab==i)[:,(0,-1)] & masksmall[1:-1,(0,-1)]).sum()
edgescore0=((lab==i)[(0,-1),:] & ~masksmall[(0,-1),1:-1]).sum() \
+ ((lab==i)[:,(0,-1)] & ~masksmall[1:-1,(0,-1)]).sum()
edgescore1=edgescore1/edgenum
edgescore0=edgescore0/edgenum
else:
edgescore0=0
edgescore1=0
#compute mask score
maskscore1=((lab==i) & masksmall[1:-1,1:-1]).sum()/(lab==i).sum()
maskscore0=((lab==i) & ~masksmall[1:-1,1:-1]).sum()/(lab==i).sum()
#compute total score
totalscore0 = split * edgescore0 + (1-split)* maskscore0
totalscore1 = split * edgescore1 + (1-split)* maskscore1
maskcopy[lab==i] = (totalscore1 > totalscore0*param)
m[x*dim:x*dim+dim, y*dim: y*dim+dim]=maskcopy
return m
def showbound(car, coordlist,dim=32):
'''Show all boundary squares of a car. Input a list of boundary squares'''
x,y,z=car.shape
thismask = np.zeros((x,y)).astype(bool)
for coord in coordlist:
x,y=coord
thismask[x*dim:x*dim+dim, y*dim: y*dim+dim]=True
showmask(car,thismask)
return None
def postprocessing(predmask,car,carbig):
predmask = thicken_shrink(predmask,5)
predmask = findcc(predmask)
predmask = refinemask(car, predmask)
predmask = unpoolarray(predmask,4)
predmask = refinemask(carbig,predmask,param=1, split=0.6)
return predmask[:,:-2]
def trainnet(filelist,
epochs, #when not training, epochs denote the number images we wish to process
batchsize=16,
load=False,
loadversion=0,
save=False,
saveversion=0,
training=True,
learning_rate = 0.0001):
#Setting up the network
tf.reset_default_graph()
height = 1280//4
width = 1920//4
channels = 3
X = tf.placeholder(tf.float32, shape=[None, height, width, channels], name = 'input')
Y = tf.placeholder(tf.float32, shape=[None, height, width, 1], name = 'target')
logits = enet(X,training=training)
error = tf.losses.sigmoid_cross_entropy(Y, logits)
train_step = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(error)
#initialization
i=0
res=pd.Series()
lenfile = len(filelist)
#Session
with tf.Session() as sess:
li = []
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
if load:
saver.restore(sess, path+'weightc'+str(loadversion))
tic = time.time()
while (i < epochs*lenfile and training):
car = readcarbatch(filelist,i%lenfile,batchsize)
carmask = readmaskbatch(filelist,i%lenfile,batchsize)
er, _=sess.run([error, train_step], feed_dict={X:car, Y:carmask})
li.append(er)
i=i+batchsize
if i%(5*batchsize)==0 and len(li) > 0:
toc = time.time()
print('Epoch',i,'Error',np.mean(li),'Time Elapsed:', toc - tic)
tic = toc
li=[]
while (not training and i < epochs):
carbig = readcar(filelist.iloc[i%lenfile],gray=False, aspect = 1)
car = preprocesscar(resizecar(carbig,4))
logit=sess.run(logits, feed_dict={X:car})[0,:,:,0]
predmask=(1/(1+np.exp(-np.clip(logit, -10,10)))).round()
predmask=postprocessing(predmask,car[0,:,:,:],carbig)
res[filelist.iloc[i%lenfile]]=predmask.copy()
i=i+1
if not training:
return res
if save:
saved = saver.save(sess, path+'weightc'+str(saveversion))
print('Weights saved to', saved)
return None